A first look at token efficiency
A while ago I saw the article Which languages are most token efficient. The article was largely discredited since it didn’t have a clear methodology. Unfortunately, I haven’t come up with one yet but I thought to do a small, anecdotal experiment comparing code generation in Haskell notebooks (with Sabela) vs Python notebooks (Marimo). Notebooks are a great environment to use with agents since they are modular by design and you can create great agent APIs on top of them. It’s also much easier to intervene as the agent is working.
My thoughts going into this were that Haskell would be more efficient because the compiler guidance would keep the AI in check as it explored. A sort of neuro-symbolic search constraint. But the ubiquity of Python, despite it being a dynamic language, means that it’s easier for LLMs to do something akin to one shotting the code.
Most of the churn seems to be the LLM trying to lookup how to do pretty simple things in Haskell. Whereas when working with Marimo pair it gets straight to the task almost without thinking about it (about 200 tokens in vs a couple of thousand in Haskell). As a result, it’s probably “cheaper” overall to use Python for arbitrary tasks at this point in time.
That said, the churn of the trial and error of dynamic languages might flip the economics for much larger projects. That’s still an open question that requires more thorough investigation. As LLMs get “better” and more software is written in more esoteric languages the gap might close. Or, more ambitiously, the gap might close if language communities trained and evaluated open source models (ethically) that are good at navigating their specific ecosystems.
You can see how the LLM solves each task in the videos below.
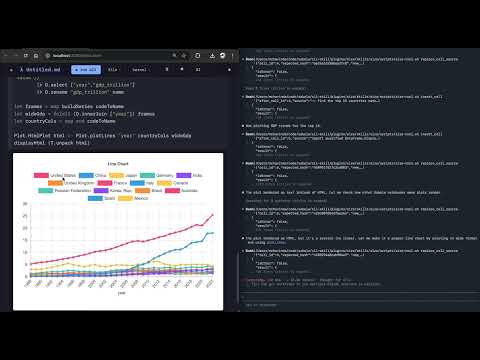
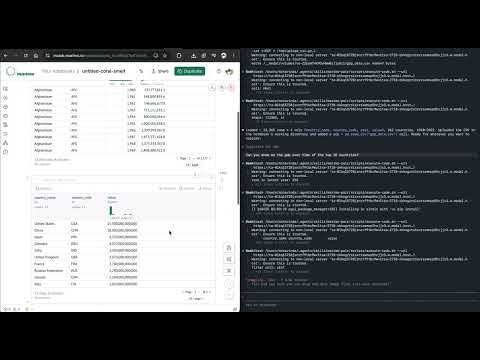
This investigation will continue more systematically in subsequent posts but I think as small as this example was it’s pretty telling.